
GitHub Discussions GraphQL API 初体验
最近在关注这个项目,看到讨论群里有 dev 表示收集到的数百条问卷数据人工处理难以应对,便萌生了帮助实现自动化的想法。
于是花了一点时间学习了 GraphQL 的基本操作,并研究了今年刚刚公测且鲜为人知的 GitHub Discussions GraphQL API, 实现了一个往 repo 中的 Discussions 上传数据 (Create Discussions) 的 PoC…… 奈何群里反应冷淡,dev 似乎忙于处理其他事务无暇顾及自动化, 就权且把大致流程写在这里吧。
配置
因为是 PoC, 所以开发环境自然越简单越好。最简单的方式当然是用 GitHub 演示用的 GraphQL Explorer,但本地配置也不难。
不过在开始之前需要先创建一个 Personal Access Token (PAT) - 教程在这里;需要注意的是作用域 (Scope)一栏需勾选 repo , write:discussion 和read:discussion。
本地配置环境的大致流程:
- 下载这个IDE
- 点 [Edit HTTP Headers], 新增一个 Header, Header name 填
Authorization, Header value 填Bearer <你的PAT>- GraphQL Endpoint 填
https://api.github.com/graphql
获取 Repository ID 和 (Discussions) Category ID
GitHub 的 API 文档里确实提供了一种创建新 Discussion 的 Mutation 模板:
1 | mutation { |
但这里的 repositoryID 和 categoryID 是什么东西呢?
也许我们只用知道他们是怎样获取的就好。
Repository ID
curl -i -u <你的GitHub用户名>:<你的PAT> 'https://api.github.com/user/repos'找到你想要的repo的信息。可能有一长串,但只看开头部分。比如:
1
2
3
4
5
6"id": 380683870,
"node_id": "MDEwOlJlcG9zaXRvcnkzODA2ODM4NzA=",
"name": "graphql-test",
"full_name": "aisuneko/graphql-test",
"private": false,
...这里的
node_id就是我们要的 Repository ID。
Category ID
运行这段 GraphQL 代码:
1
2
3
4
5
6
7
8
9
10query {
repository(owner: "<你的用户名>", name: "<你的 repo 的名称>") {
discussionCategories(first: 10) {
nodes {
id
name
}
}
}
}在输出中找到你想创建的新 Discussion 应该属于的 Category, 下面的
id就是我们要的 Category ID。
实际操作
实际创建新 Discussion 的代码非常简单:
1 | mutation { |
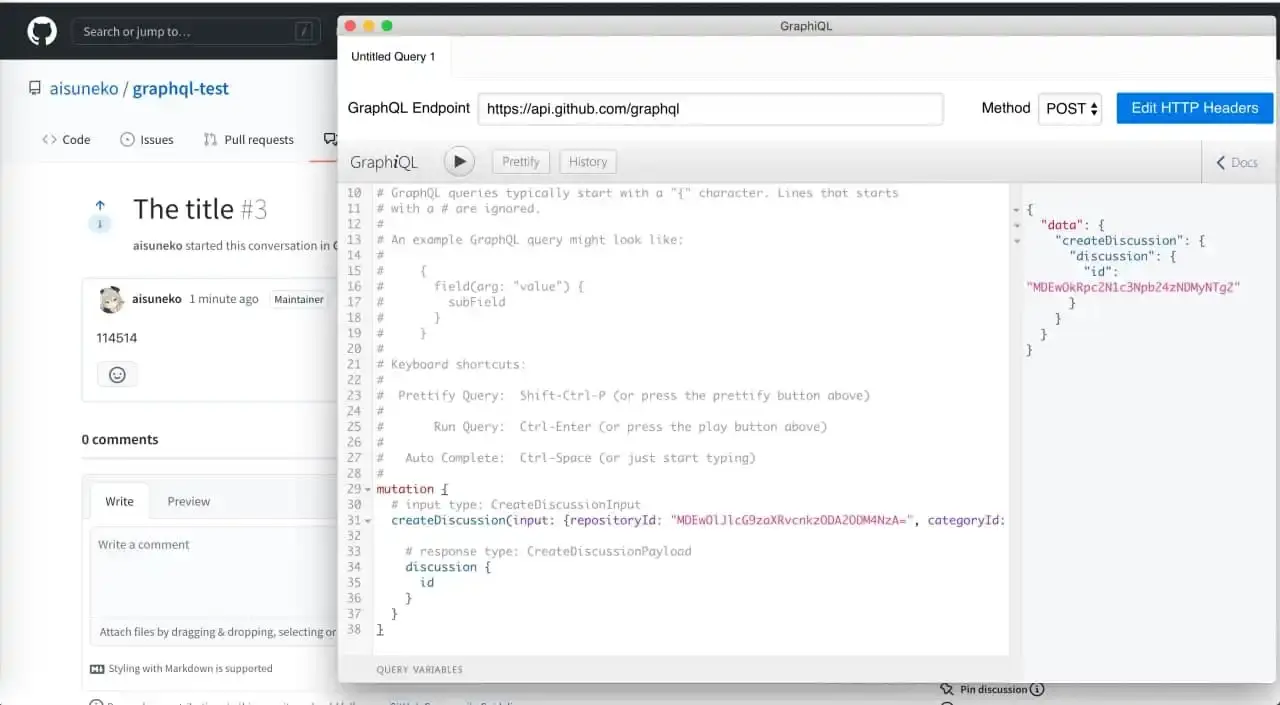
对,就这么简单(
What’s next?
上面提到 dev 把自动化的方案搁置了,所以没进一步研究读取数据和脚本集成 (Python, JavaScript……) 之类的…… 不过真正实现起来应该也不难。
这个方案对于其他类型的请求应该也是通用的。
不过我还是对全栈开发一窍不通